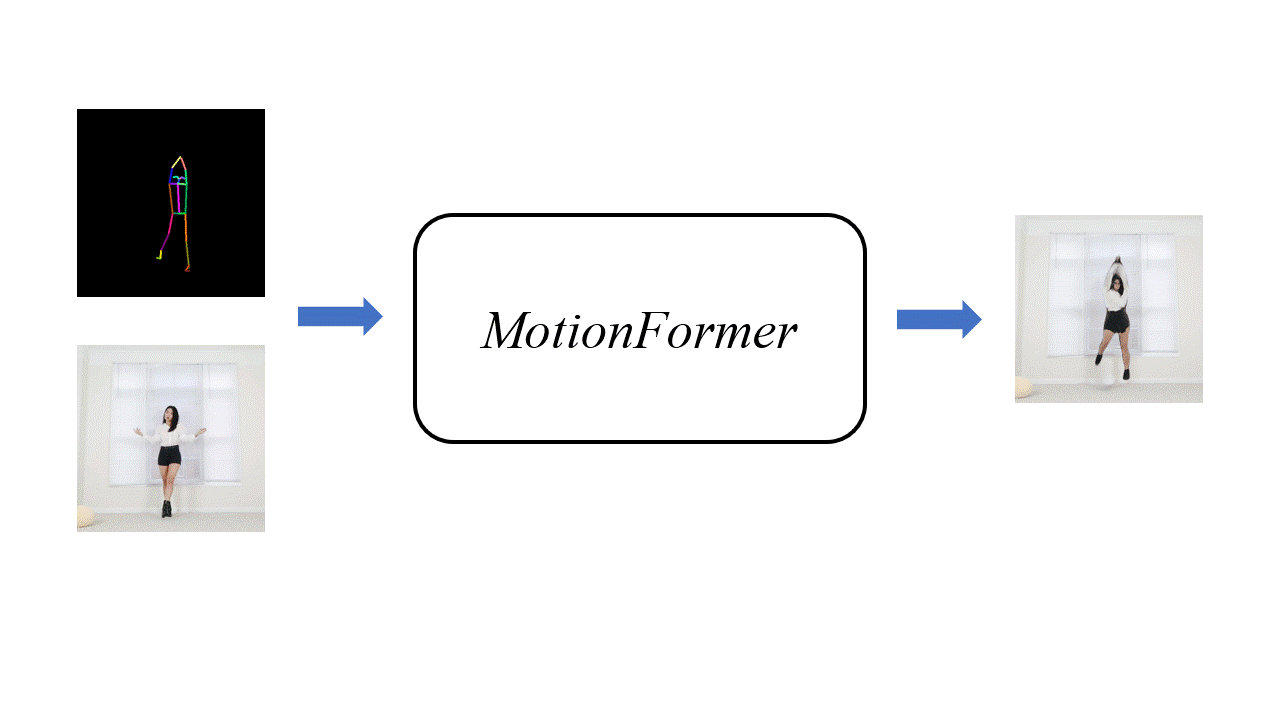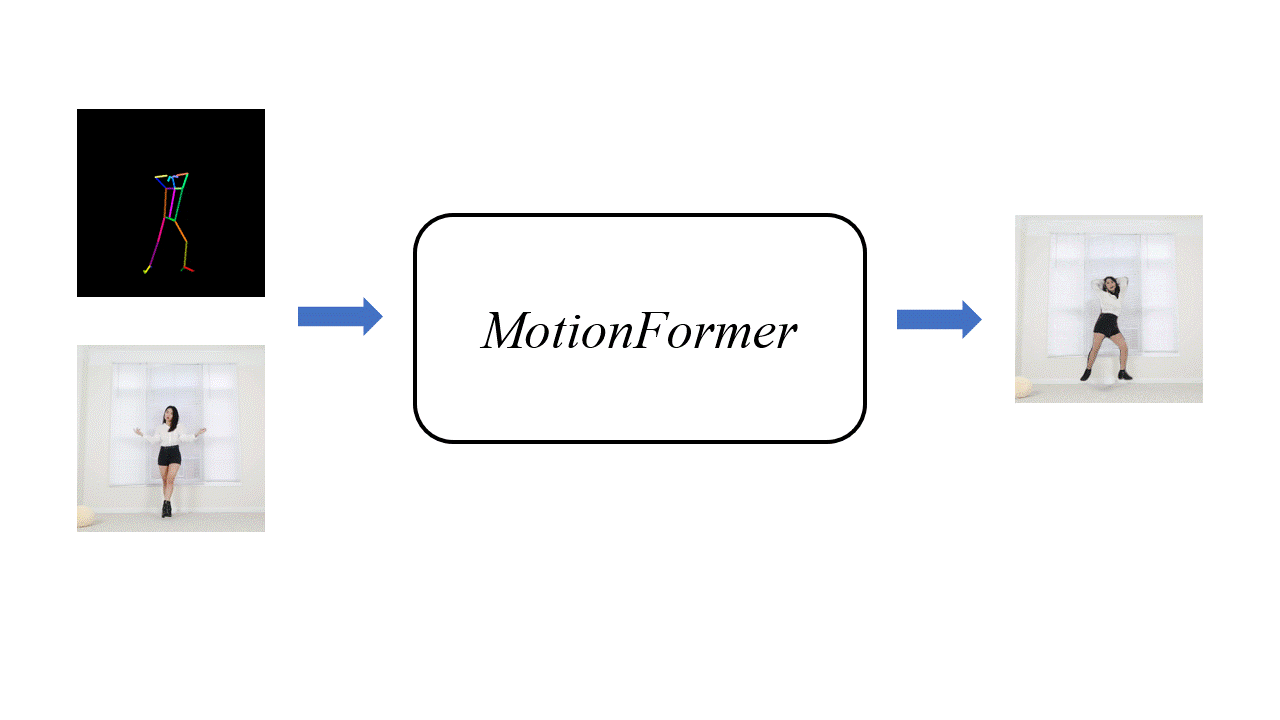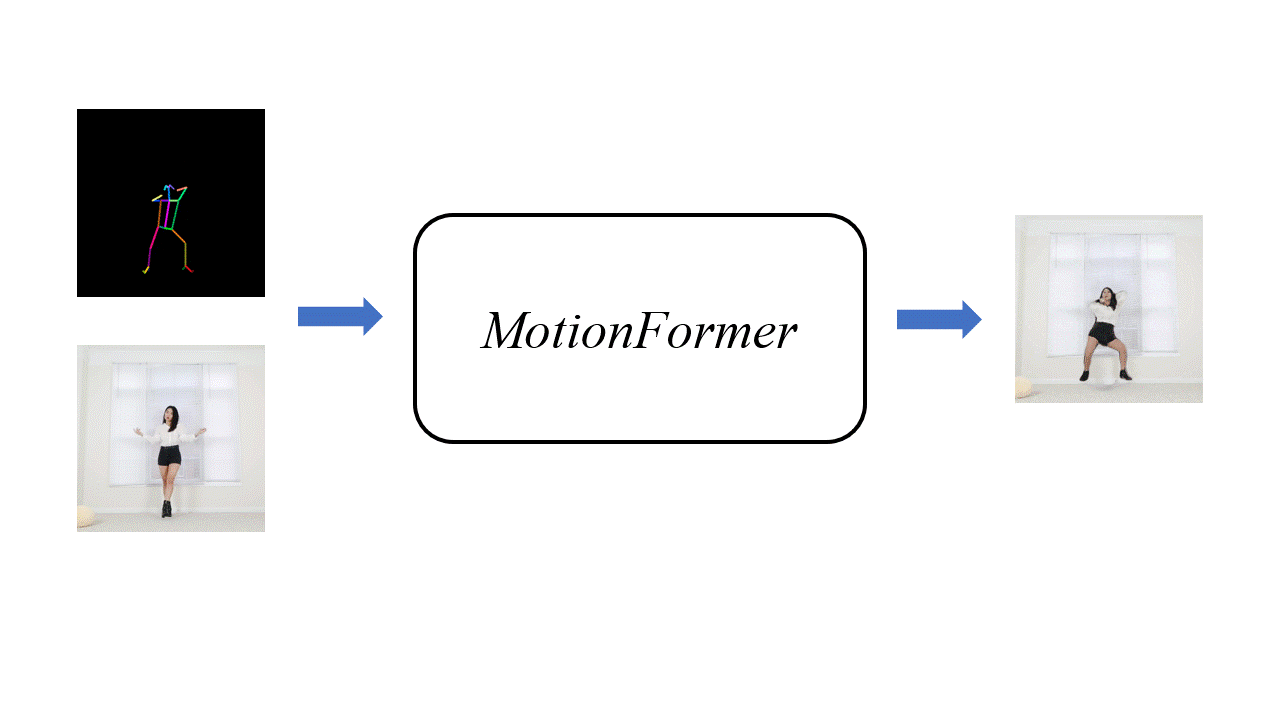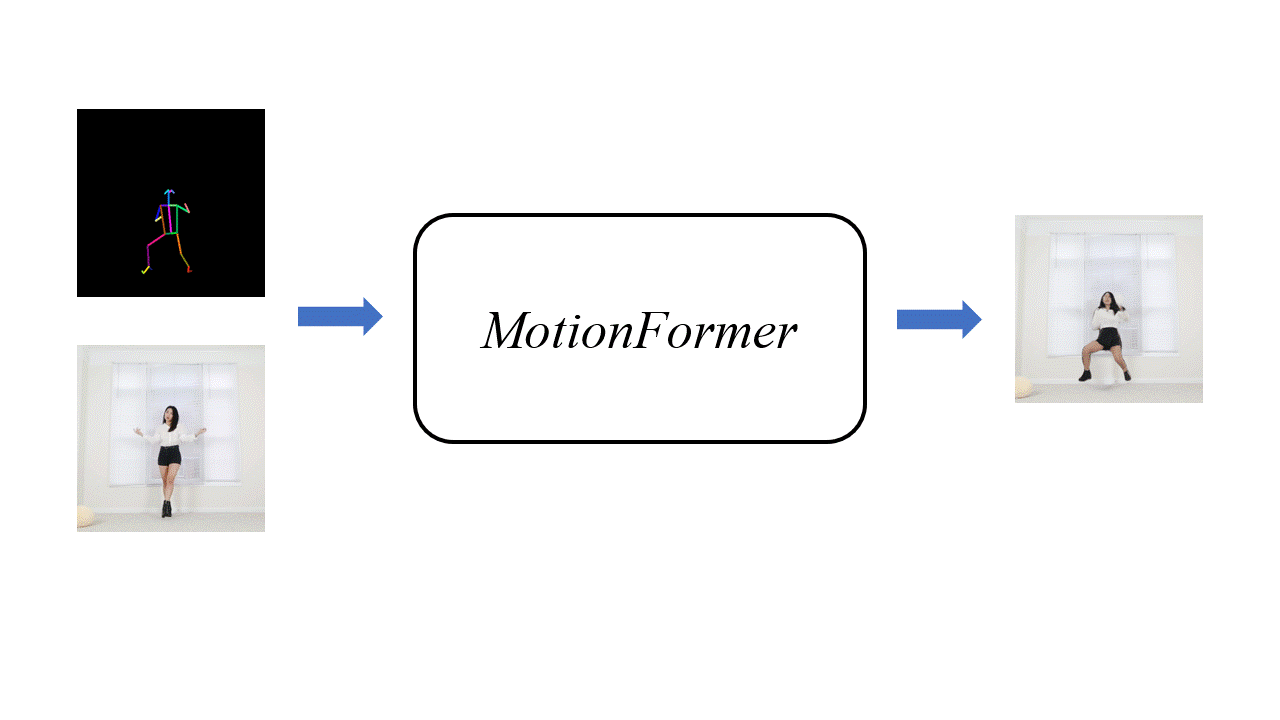
Motivation
Human motion transfer aims to transfer motions from a target dynamic person to a source static one for motion synthesis. An accurate matching between the source person and the target motion in both large and subtle motion changes is vital for improving the transferred motion quality. In this paper, we propose Human MotionFormer, a hierarchical ViT framework that leverages global and local perceptions to capture large and subtle motion matching, respectively. It consists of two ViT encoders to extract input features (i.e., a target motion image and a source human image) and a ViT decoder with several cascaded blocks for feature matching and motion transfer. In each block, we set the target motion feature as Query and the source person as Key and Value, calculating the cross-attention maps to conduct a global feature matching. Further, we introduce a convolutional layer to improve the local perception after the global cross-attention computations. This matching process is implemented in both warping and generation branches to guide the motion transfer. During training, we propose a mutual learning loss to enable the co-supervision between warping and generation branches for better motion representations. Experiments show that our Human MotionFormer sets the new state-of-the-art performance both qualitatively and quantitatively.
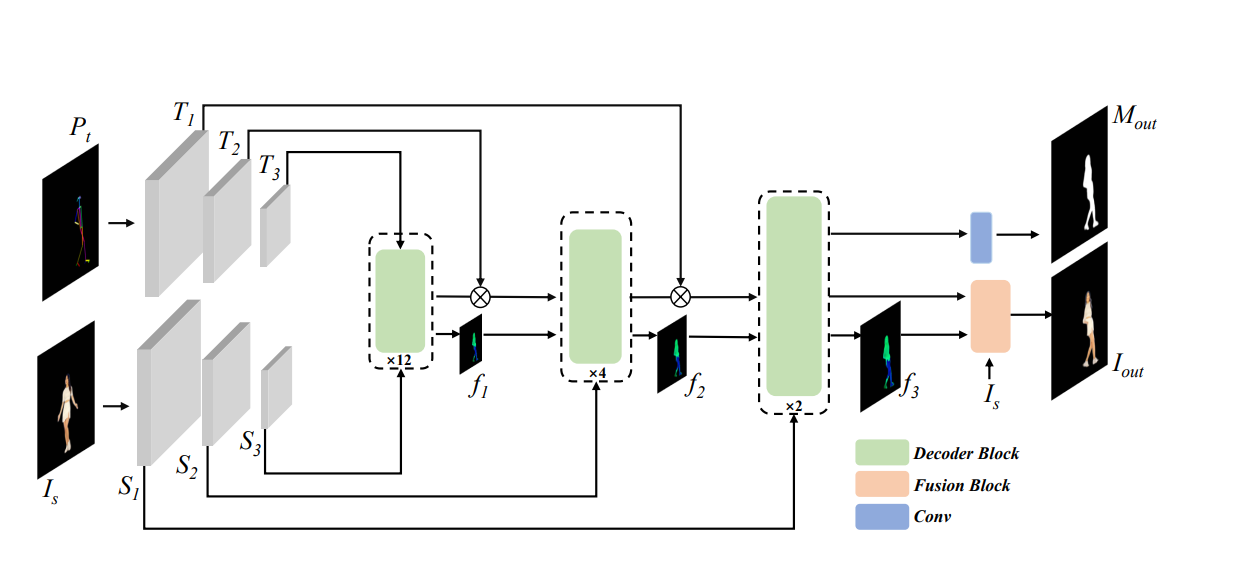
Overview of our MotionFormer framework. We use two Transformer encoders to extract features of the source image Is and the target pose image Pt. These two features are hierarchically combined in one Transformer decoder where there are multiple decoder blocks. Finally, a fusion block synthesizes the output image by blending the warped and generated images.
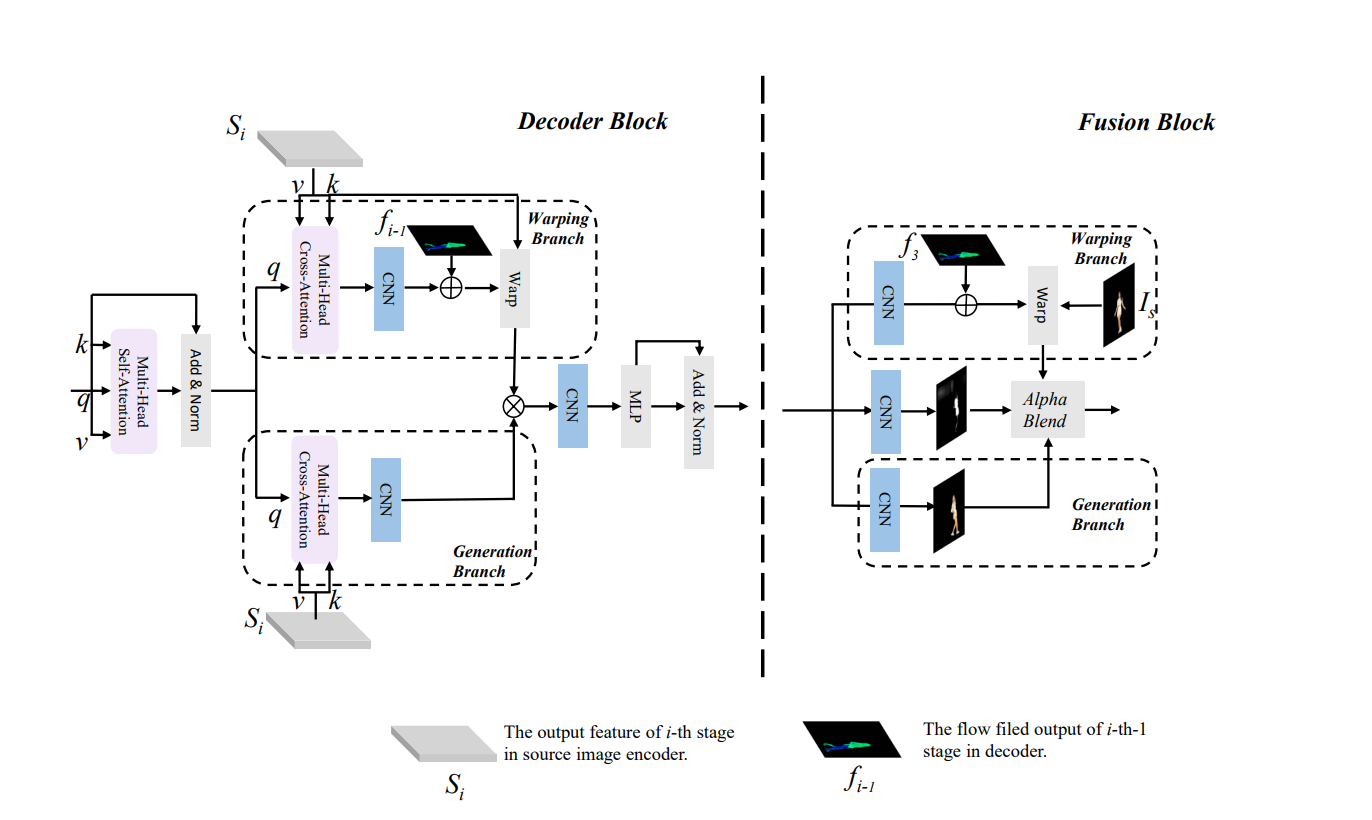
Overview of our decoder and fusion blocks. There are warping and generation branches in these two blocks. In decoder block, We build the global and local correspondence between source image and target pose with Multi-Head Cross-Attention and CNN respectively. The fusion block predict an mask to combine the output of two branches in pixel level.



@article{liu2023human,
title={Human MotionFormer: Transferring Human Motions with Vision Transformers},
author={Liu, Hongyu and Han, Xintong and Jin, ChengBin and Wei, Huawei and Lin, Zhe and Wang, Faqiang and Dong, Haoye and Song, Yibing and Xu, Jia and Chen, Qifeng},
journal={arXiv preprint arXiv:2302.11306},
year={2023}
}